Contenu
- Définition - Que signifie Apache Kudu?
- Introduction à Microsoft Azure et au nuage Microsoft | Tout au long de ce guide, vous apprendrez ce qu'est le cloud computing et comment Microsoft Azure peut vous aider à migrer et à exploiter votre entreprise à partir du cloud.
- Techopedia explique Apache Kudu
Définition - Que signifie Apache Kudu?
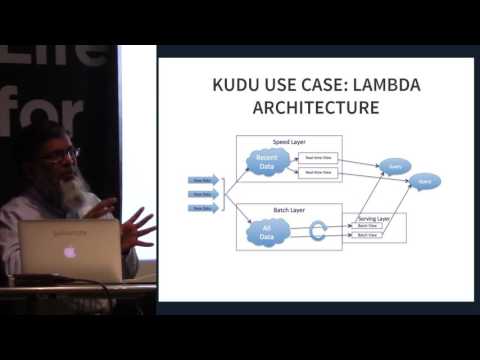
Apache Kudu est un membre de l'écosystème open source Apache Hadoop. Il s'agit d'un moteur de stockage open source destiné aux données structurées prenant en charge l'accès aléatoire à faible latence ainsi que des modèles d'accès analytiques efficaces. Il a été conçu et mis en œuvre pour combler le fossé entre le système HDFS (Hadoop Distributed File System) largement utilisé et la base de données HBase NoSQL. Bien que ces systèmes puissent encore s'avérer avantageux, Apache Kudu peut prendre en charge de nombreuses charges de travail courantes, car il simplifie considérablement leur architecture.
Introduction à Microsoft Azure et au nuage Microsoft | Tout au long de ce guide, vous apprendrez ce qu'est le cloud computing et comment Microsoft Azure peut vous aider à migrer et à exploiter votre entreprise à partir du cloud.
Techopedia explique Apache Kudu
Apache Kudu a été principalement développé en tant que projet à Cloudera. À ce jour, la plupart des contributions ont été fournies par des développeurs employés par Cloudera. Lors de sa publication, seuls les fichiers binaires de commodité étaient inclus dans les référentiels de Cloudera. Toutefois, le processus de publication du code source d’Apache Software Foundation (ASF) a été adopté lors de sa participation à l’incubateur. Il est spécialement conçu pour les cas d'utilisation nécessitant une analyse rapide sur des données rapides. Il a été conçu pour tirer parti du matériel de nouvelle génération et du traitement en mémoire. Il réduit considérablement le temps de latence des requêtes pour Apache Impala et Apache Spark. Il distribue les données via un moteur de stockage en colonnes ou via un partitionnement horizontal, puis réplique chaque partition à l'aide du consensus Raft, offrant ainsi un temps de récupération moyen et des latences de fin de ligne faibles.
Bien que Kudu soit un produit conçu dans le contexte de l’écosystème Apache Hadoop, il prend également en charge l’intégration avec d’autres projets d’analyse de données entrant et sortant de la base de données ASF.
Apache Kudu se révèle efficace car il peut traiter des charges de travail analytiques en temps réel sur une seule couche de stockage, offrant ainsi aux architectes la flexibilité nécessaire pour traiter un plus grand nombre de cas d'utilisation sans solutions de contournement exotiques.